ساخت ایجنت هوشمند اختصاصی در سال 1404: ترکیب n8n با OpenAI Assistant و حافظه بلندمدت
چتباتهای مبتنی بر یک فراخوانی ساده API به مدل GPT دیگر پاسخگوی نیازهای پیچیده B2B نیستند. این ابزارها فاقد حافظه بلندمدت و توانایی اجرای وظایف معین هستند.
هر بار که کاربر پیامی ارسال میکند، مکالمه از نقطه صفر شروع میشود و هزینه توکنها برای ارسال مجدد تاریخچه گفتگو به سرعت از کنترل خارج میگردد. برای وظایف واقعی کسبوکار – مانند استعلام موجودی از یک انبار، تحلیل یک فایل گزارش فروش، یا ثبت یک تیکت پشتیبانی در سیستم CRM – این رویکرد ناکارآمد و محدود است.
راهحل، ساخت یک «ایجنت» (Agent) است، نه یک چتبات ساده. یک ایجنت واقعی دارای حافظه پایدار، ابزارهای قابل اجرا و یک منطق مرکزی برای ارکستراسیون است.
در این راهنمای فنی، ما در کارورا نشان میدههیم چگونه با ترکیب n8n به عنوان ارکستراتور، OpenAI Assistants API به عنوان موتور استدلال، و مکانیزم Retrieval داخلی آن به عنوان حافظه، یک ایجنت هوش مصنوعی (AI Agent) کاملاً اختصاصی و تحت کنترل خودتان بسازید.
معماری ایجنت هوشمند مدرن: n8n، OpenAI و حافظه پایدار

قبل از ورود به جزئیات پیادهسازی، درک معماری سیستم ضروری است. این معماری بر سه اصل استوار است: تفکیک وظایف (Separation of Concerns)، کنترل کامل بر منطق اجرا، و قابلیت گسترشپذیری.
دیاگرام معماری سیستم:
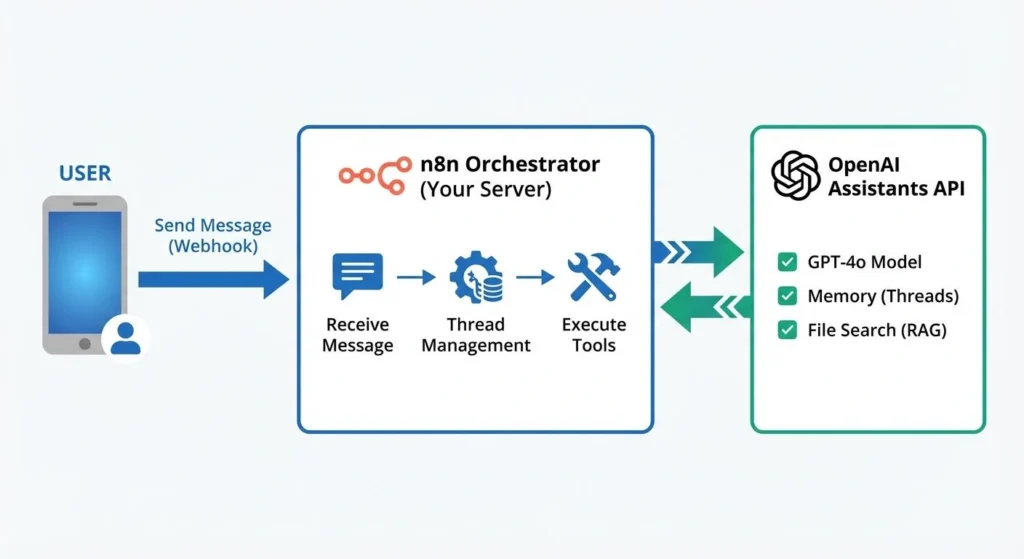
اجزای کلیدی:
1. n8n (Orchestrator): این ابزار متنباز و Self-hosted، قلب تپنده سیستم ماست. n8n برخلاف ابزارهای SaaS مانند Zapier، به شما کنترل کامل بر ورکفلوها، مدیریت خطا و اتصال به سرویسهای داخلی (on-premise) را میدهد. در این معماری، n8n مسئول دریافت درخواستها، مدیریت شناسههای مکالمه (Thread IDs) و اجرای منطق پیچیدهتر مانند فراخوانی APIهای دیگر به عنوان ابزار (Custom Tools) است.
2. OpenAI Assistants API: این صرفاً یک API برای مدل زبان نیست؛ Assistants API یک چارچوب کامل برای ساخت ایجنت است. این سرویس، مدیریت State مکالمه (Threads) را به صورت داخلی انجام میدهد و ما را از ارسال مجدد کل تاریخچه گفتگو بینیاز میکند. همچنین ابزارهای قدرتمندی مانند Code Interpreter و Retrieval (برای پیادهسازی RAG) را به صورت پیشفرض در اختیار ما قرار میدهد.
3. حافظه پایدار (Retrieval): با آپلود فایلهای دانش (PDF, DOCX, JSON, …) در Assistant، مدل میتواند اطلاعات را از این منابع استخراج کرده و برای پاسخدهی استفاده کند. این مکانیزم، یک پیادهسازی مدیریتشده از Retrieval-Augmented Generation (RAG) است که ایجنت را به دانش اختصاصی کسبوکار شما مجهز میکند.
این ترکیب، بهینهترین حالت ممکن را ارائه میدهد: قدرت استدلال و ابزارهای مدیریتشده OpenAI در کنار انعطافپذیری و کنترل مطلق n8n.
قدم اول: راهاندازی و پیکربندی OpenAI Assistant

ابتدا باید یک Assistant در پلتفرم OpenAI ایجاد کنیم. این Assistant به عنوان الگوی اولیه برای تمام تعاملات ایجنت ما عمل خواهد کرد.
1. وارد داشبورد OpenAI شده و به بخش Assistants بروید.
2. روی دکمه Create کلیک کنید.
3. Name: یک نام مشخص برای ایجنت خود انتخاب کنید (مثلاً Karvara_Support_Agent).
4. Instructions (System Prompt): این بخش حیاتی است. در اینجا شخصیت، وظایف و محدودیتهای ایجنت را تعریف میکنید. برای مثال:
You are a technical support agent for Karora. Your primary goal is to answer user questions based on the provided documentation. If a user asks about product pricing, you must use the 'get_live_price' tool. Do not answer questions outside of your knowledge base. Always be concise and professional.
5. Model: مدل مورد نظر خود را انتخاب کنید (مثلاً gpt-4o).
6. Tools: ابزارهای مورد نیاز را فعال کنید. برای شروع، Retrieval را فعال کنید. این قابلیت به ایجنت اجازه میدهد تا از فایلهایی که شما آپلود میکنید برای پاسخدهی استفاده کند.
7. Files: در این بخش میتوانید فایلهای دانش (مثلاً کاتالوگ محصولات، راهنمای فنی) را آپلود کنید. فعلاً این بخش را خالی بگذارید تا در قدم سوم به آن بپردازیم.
8. Save: پس از ذخیره، یک Assistant ID (با پیشوند asst_...) به شما داده میشود. این شناسه را کپی کنید؛ در ورکفلو n8n به آن نیاز خواهیم داشت.
نکته امنیتی مهم: کلید API خود (API Key) را هرگز به صورت مستقیم در نودهای n8n وارد نکنید. آن را در بخش Credentials > New > OpenAI API ذخیره کنید تا به صورت رمزنگاریشده نگهداری شود.
قدم دوم: ساخت ورکفلو پایه در n8n برای مدیریت مکالمه
این بخش هسته اصلی پیادهسازی است. یک ورکفلو میسازیم که پیام کاربر را دریافت کرده، مکالمه را مدیریت میکند و پاسخ را برمیگرداند.
دیاگرام ورکفلو در n8n:
[Webhook Trigger] -> [OpenAI Assistant Node] -> [Set Node for Response]
۱. Trigger Node: Webhook
{
"question": "اطلاعات محصول X چیست؟",
"threadId": "thread_abc123" // اختیاری، برای ادامه مکالمه
}
⚠️ نکته امنیتی: وبهوکها به صورت پیشفرض عمومی هستند. برای محیطهای پروداکشن، حتماً از بخش تنظیمات وبهوک، گزینه Authentication را فعال کرده و از یک Header امنیتی (مانند X-API-KEY) برای اعتبارسنجی درخواستها استفاده کنید.
۲. OpenAI Assistant Node
Resource آن را روی Assistant تنظیم کنید.Use Existing Assistant and Add Message to Thread را انتخاب کنید.asst_...) را در این فیلد وارد کنید.threadId در ورودی Webhook وجود داشت، از آن استفاده کند؛ در غیر این صورت، یک Thread جدید بسازد. برای این کار از یک Expression استفاده میکنیم:
{{ $json.body.threadId || '' }}
اگر threadId در ورودی موجود باشد، از آن استفاده میشود. اگر نباشد، مقدار خالی ('') به نود ارسال شده و نود OpenAI به طور خودکار یک Thread جدید ایجاد میکند.
{{ $json.body.question }}
۳. Set Node: فرمتبندی خروجی
نود OpenAI Assistant خروجی پیچیدهای دارد. ما برای ارسال یک پاسخ تمیز به کاربر، تنها به محتوای آخرین پیام و threadId نیاز داریم.
response با مقدار زیر ایجاد کنید. این Expression آخرین پیام اضافه شده توسط assistant را از آرایه پیامها استخراج میکند:
{{ $json.data[0].content[0].text.value }}
threadId برای ارسال به فرانتاند ایجاد کنید تا در درخواستهای بعدی استفاده شود:
{{ $json.body.threadId || '' }}
ورکفلو پایه شما آماده است. با ارسال یک درخواست به URL وبهوک، ایجنت پاسخ میدهد و threadId را برای ادامه گفتگو برمیگرداند.
ورکفلو آماده n8n را دانلود کنید
چرا از صفر شروع کنید؟ این ورکفلو تستشده را در n8n خود ایمپورت کرده و ساخت ایجنت هوش مصنوعی را در چند دقیقه آغاز کنید.
کد JSON ورکفلو برای Import:
{
"name": "Karvara - Basic AI Agent",
"nodes": [
{
"parameters": {},
"name": "Start",
"type": "n8n-nodes-base.start",
"typeVersion": 1,
"position": [250, 300]
},
{
"parameters": {
"path": "ai-agent-webhook",
"options": {}
},
"name": "Webhook",
"type": "n8n-nodes-base.webhook",
"typeVersion": 1,
"position": [450, 300],
"webhookId": "your-webhook-id-here"
},
{
"parameters": {
"resource": "assistant",
"operation": "useAssistantAddMessage",
"assistantId": "asst_YOUR_ASSISTANT_ID_HERE",
"threadId": "{{ $json.body.threadId || '' }}",
"message": "{{ $json.body.question }}"
},
"name": "OpenAI Assistant",
"type": "n8n-nodes-base.openAi",
"typeVersion": 2,
"position": [650, 300],
"credentials": {
"openAiApi": {
"id": "your-credential-id-here",
"name": "OpenAI account"
}
}
},
{
"parameters": {
"values": {
"string": [
{
"name": "response",
"value": "{{ $json.data[0].content[0].text.value }}"
},
{
"name": "threadId",
"value": "{{ $json.thread_id }}"
}
]
},
"options": {
"keepOnlySet": true
}
},
"name": "Format Response",
"type": "n8n-nodes-base.set",
"typeVersion": 2,
"position": [850, 300]
}
],
"connections": {
"Webhook": {
"main": [[{"node": "OpenAI Assistant", "type": "main", "index": 0}]]
},
"OpenAI Assistant": {
"main": [[{"node": "Format Response", "type": "main", "index": 0}]]
}
}
}
قدم سوم: تجهیز ایجنت به حافظه بلندمدت با مکانیزم Retrieval
در این مرحله، به ایجنت دانش اختصاصی تزریق میکنیم تا از یک ربات عمومی به یک متخصص مجازی تبدیل شود.
1. به داشبورد OpenAI و تنظیمات Assistant خود بازگردید.
2. در بخش Files، روی Upload کلیک کرده و یک فایل PDF حاوی اطلاعات فنی محصولات شرکت خود را آپلود کنید.
3. مطمئن شوید که ابزار Retrieval همچنان فعال است.
4. Assistant را ذخیره کنید.
تست عملی:
حالا یک درخواست جدید به Webhook ورکفلو خود ارسال کنید و سوالی بپرسید که پاسخ آن منحصراً در فایل PDF شما وجود دارد.
مثال درخواست:
{
"question": "حداکثر فشار عملیاتی برای مدل پمپ K-500 چقدر است؟",
"threadId": "" // Start a new conversation
}
نتیجه مورد انتظار:
ایجنت باید فایل PDF را جستجو کرده و پاسخ دقیق را استخراج کند (مثلاً: «حداکثر فشار عملیاتی برای مدل پمپ K-500 طبق داکیومنت، 25 بار است.»). این اثبات میکند که مکانیزم RAG به درستی کار میکند. در تجربه ما در کارورا، این روش برای ساخت ایجنتهای پشتیبانی فنی و پاسخگویی به سوالات متداول مشتریان بسیار کارآمد است.
قدم چهارم: ارتقاء AI Agents با ابزارهای اختصاصی (Custom Tools)
قدرت واقعی این معماری زمانی آشکار میشود که ایجنت بتواند با سیستمهای دیگر تعامل کند. ما یک ابزار سفارشی تعریف میکنیم که قیمت لحظهای یک محصول را از یک API دیگر استعلام میکند.
۱. تعریف Function در OpenAI Assistant
{
"name": "get_live_price",
"description": "Get the real-time price of a specific product by its SKU.",
"parameters": {
"type": "object",
"properties": {
"sku": {
"type": "string",
"description": "The product SKU, e.g., 'KV-PROD-001'."
}
},
"required": ["sku"]
}
}
۲. بروزرسانی ورکفلو n8n برای مدیریت Tool Calls
ورکفلو را طوری تغییر میدهیم که بتواند درخواست اجرای ابزار را تشخیص داده و آن را اجرا کند.
دیاگرام ورکفلو جدید:
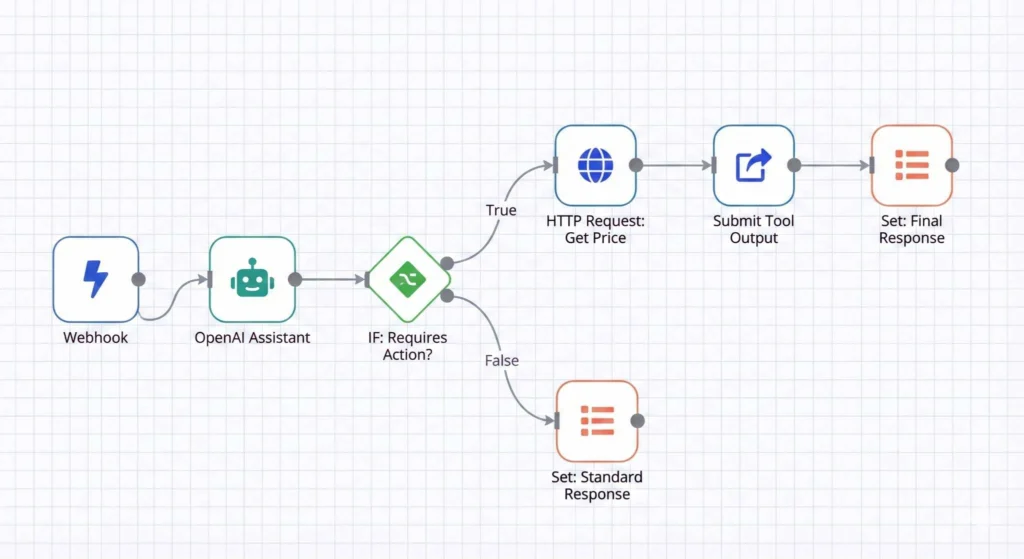
1. IF Node: بعد از نود OpenAI Assistant، یک نود IF اضافه کنید. شرط آن را طوری تنظیم کنید که بررسی کند آیا خروجی Assistant نیازمند اجرای یک ابزار است یا خیر.
{{ $json.status }} Equals requires_action2. شاخه True (اجرای ابزار):
true از نود IF متصل میشود. فرض کنید API قیمتدهی شما در آدرس https://api.karvara.com/price قرار دارد.https://api.karvara.com/price?sku={{ $json.required_action.submit_tool_outputs.tool_calls[0].function.arguments.sku }}AssistantSubmit Tool Outputs to Run{{ $('OpenAI Assistant').item.json.thread_id }} (از خروجی نود اول Assistant){{ $('OpenAI Assistant').item.json.id }} (از خروجی نود اول Assistant)HTTP Request را به همراه tool_call_id به OpenAI برگردانیم.
[
{
"tool_call_id": "{{ $('OpenAI Assistant').item.json.required_action.submit_tool_outputs.tool_calls[0].id }}",
"output": "{{ $('HTTP Request').item.json.price }}"
}
]
این نود نتیجه را برای Assistant ارسال میکند تا او پاسخ نهایی را با استفاده از این اطلاعات تولید کند.
3. شاخه False (پاسخ مستقیم):
با این ساختار، هرگاه کاربر در مورد قیمت سوال کند (مثلاً «قیمت محصول KV-PROD-001 چنده؟»)، مدل تابع get_live_price را فراخوانی میکند، n8n آن را اجرا کرده، نتیجه را به مدل برمیگرداند و مدل پاسخ نهایی را تولید میکند: «قیمت لحظهای محصول KV-PROD-001، مبلغ ۱,۵۴۰,۰۰۰ تومان است.»
نتیجهگیری: شما یک ایجنت خودکار ساختید، نه یک ربات ساده
با دنبال کردن این راهنما، شما یک چتبات ساده نساختهاید؛ شما یک ایجنت هوش مصنوعی (AI Agent) با معماری مدرن پیادهسازی کردهاید که دارای ویژگیهای زیر است:
این معماری نقطه شروعی برای ساخت سیستمهای بسیار پیچیدهتر است. در پروژههای واقعی دیدهایم که با اتصال این ایجنت به APIهای داخلی شرکتها (مانند سیستمهای ERP و CRM)، میتوان فرآیندهای کسبوکار را به شکل چشمگیری خودکار و بهینه کرد. چالشهای بعدی شما مدیریت هزینه API در مقیاس بالا و بهینهسازی تاخیر (Latency) در پاسخدهی خواهد بود که نیازمند استراتژیهای Caching و بهینهسازی ورکفلو است.
ایده خود را به یک پروژه واقعی تبدیل کنید
ساخت نمونه اولیه یک چیز است، و پیادهسازی یک ایجنت هوشمند امن و مقیاسپذیر چیز دیگر. هنوز مطمئن نیستید؟ بیایید ۱۵ دقیقه رایگان در مورد کسبوکار و چالشهای شما صحبت کنیم.
سوالات متداول
هزینه استفاده از Assistants API در مقایسه با Chat Completion API چگونه است؟
Assistants API معمولاً گرانتر است. هزینه آن شامل سه بخش است: هزینه توکنهای ورودی و خروجی (مشابه Chat Completion)، یک هزینه ثابت به ازای هر مکالمه (Thread) فعال، و هزینه استفاده از ابزارهایی مانند Code Interpreter و Retrieval (به ازای هر گیگابایت فایل در ساعت). برای وظایف ساده و بدون نیاز به حافظه، Chat Completion ارزانتر است. برای کاربردهای ایجنت-محور، هزینه اضافی Assistants API با صرفهجویی در مدیریت State و توسعه جبران میشود.
مدیریت State یا همان Thread ID در سمت کلاینت (Front-end) چگونه باید انجام شود؟
ورکفلو n8n در هر پاسخ، threadId مربوط به آن مکالمه را برمیگرداند. اپلیکیشن کلاینت شما (مثلاً یک وب اپلیکیشن چت) باید این شناسه را ذخیره کرده (مثلاً در Local Storage) و در درخواستهای بعدی همان کاربر، آن را مجدداً به Webhook ارسال کند. این کار تضمین میکند که هر کاربر در ادامه مکالمه قبلی خود قرار میگیرد.
آیا میتوان از مدلهای زبان محلی (Local LLMs) به جای OpenAI در این معماری استفاده کرد؟
بله، اما با پیچیدگی بیشتر. n8n نودهایی برای مدلهای محلی مانند Ollama دارد. در این حالت، شما باید منطق مدیریت State (مشابه Threads) و اجرای ابزارها (مشابه Function Calling) را خودتان در ورکفلو n8n پیادهسازی کنید. برای مثال، میتوانید تاریخچه گفتگو را در یک دیتابیس Redis یا PostgreSQL ذخیره کرده و قبل از هر فراخوانی مدل، آن را بازیابی کنید. قدرت Assistants API در این است که این پیچیدگیها را به صورت مدیریتشده ارائه میدهد.
تفاوت اصلی این رویکرد با استفاده از فریمورکهایی مانند LangChain یا LlamaIndex چیست؟
LangChain و LlamaIndex کتابخانههای کد-محور (code-centric) برای ساخت اپلیکیشنهای مبتنی بر LLM هستند. آنها انعطافپذیری بسیار بالایی در سطح کد ارائه میدهند اما نیازمند مهارت برنامهنویسی عمیق هستند. رویکرد n8n یک راهکار بصری و مبتنی بر ورکفلو (low-code) است که ارکستراسیون و اتصال بین سرویسها را بسیار سادهتر و سریعتر میکند. برای تیمهایی که میخواهند به سرعت یک ایجنت را به مرحله تولید برسانند، n8n اغلب گزینه بهینهتری است.